其实我对写测试代码很抵触,因为本来写一个项目就很难了,还要写测试代码,最烧脑的就是写测试用例,想着就头疼。
问了一下chatgpt该怎么解决。
最后我来说一句,不要被测试吓到了,写想得到的测试用例即可,因为即使是AWS这样的大厂,也会因为时间不够而测试不够,所以放松点,写就行了,测试用例本身也不是万能的。
现在的AI时代,更不用担心写测试代码了,把代码交给AI,叫它们给出测试代码先打个样,我照着样子写就行了。
🧘♂️ 一、先接受一个现实
“不是所有代码都值得被测试。”
👉 不是让你覆盖全部。测试是一个投资,要投入少、回报高。 只测:
- ❗️会出错的地方(比如 API 请求、复杂逻辑、权限判断)
- ✅ 核心功能(用户注册、下单、提交表单)
- 🚫 不测(纯展示组件、样式、动画)
📊 实际经验法则:
一个成熟的前端项目,测试覆盖率达到 60% 就很优秀了。
🪄 二、换个思路:测试 ≠ 写更多代码
可以把测试当成「自动化的手工测试」。
比如,你现在开发时是不是会这样:
- 打开浏览器
- 点击按钮
- 看看列表是不是更新了
那么测试其实就是:
xxxxxxxxxx21fireEvent.click(button);2expect(screen.getByText('新英雄')).toBeInTheDocument();💡 就是把“自己手点”的流程,变成一段能自动跑的脚本。 以后你改完代码,它自己帮你点一遍,比你手动测试强多了。
🧩 三、从小处入手(5分钟入门计划)
你只需要写 第一个最简单的测试,就能缓解90%的“抗拒感”。
👇 示例:
xxxxxxxxxx71import { render, screen } from '@testing-library/react';2import { Button } from './Button';34test('renders button with label', () => {5render(<Button label="Click me" />);6expect(screen.getByText(/Click me/i)).toBeInTheDocument();7});✅ 不需要 mock ✅ 不需要配置 CI ✅ 只需要看到测试通过的 ✅ 绿色标志,你就会开始“有点爽” 😄
⚙️ 四、逐渐提升节奏(循序渐进)
阶段 目标 行动 🥉 第1阶段 学会写最简单的组件测试 测按钮、输入框 🥈 第2阶段 学会 mock API 用 MSW 模拟接口 🥇 第3阶段 学会测试 React Query / Mutation 验证数据流更新 🏆 第4阶段 集成到 CI 每次提交自动测试 🔧 五、写测试的小技巧
技巧 说明 ✅ 用“行为”命名测试 比如: it("should add hero when button clicked")🔁 不写长测试 每个测试只验证一件事 🧠 模拟真实用户 使用 fireEvent.change()、fireEvent.click()⏱ 跑测试快 Vitest 比 Jest 快好几倍 🛠 遇到难测的逻辑? 提取成纯函数再单测就行 💬 六、再来点鸡汤(但是真实的)
“没有测试的代码,就像一栋没人检查的房子:看着挺好,其实地基可能歪了。”
很多团队直到出 bug 才后悔:
- 改一个小功能,另一个页面崩了;
- 改个接口字段,整站 404;
- 加个条件判断,性能暴跌;
测试其实是:
花一点点时间,现在安心; 不写测试,将来加班调 bug。
❤️ 七、最实用的策略总结
目标 做法 想轻松上手 从最简单的组件测试写起 想测试 API 用 MSW 模拟接口 想避免回归 bug 测核心逻辑(useQuery、mutation) 没动力 跑一次自动测试,看一堆 ✅ 绿点就上头了 😆 测试代码需要些很多测试用例吗?
🧩 一、先说结论:不是测试越多越好,而是要写“有价值的测试”
✅ 写 3 个关键测试比写 30 个无用测试更重要。
测试的数量 ≠ 质量。 关键是要“覆盖可能出 bug 的分支”。
🎯 二、测试用例的目标:验证行为,而不是代码行
很多初学者会这样想:
“每个函数我都写几个测试,这样安全。”
其实不对。 真正有价值的测试,是验证预期行为是否成立。
举个例子 👇
xxxxxxxxxx41function getDiscount(price: number, isMember: boolean) {2if (isMember) return price * 0.9;3return price;4}很多人会写:
xxxxxxxxxx21test('getDiscount returns 90% for member', () => {...});2test('getDiscount returns 100% for non-member', () => {...});这样就够了 ✅ 不需要再测负数、NaN、undefined —— 因为在业务上不会发生这些输入。
测试的目标是“确保真实用户不会踩坑”, 不是“证明代码对所有可能输入都无敌”。
⚙️ 三、那到底要写多少测试用例?(经验法则)
业务复杂度 建议的测试数量 举例 简单函数 1~2 个 加法、纯展示逻辑 有分支逻辑的函数 每个分支 1 个 登录成功 / 失败 表单 3~4 个 输入验证、提交、错误信息 API 请求 2~3 个 成功响应 / 失败响应 UI 交互(点击/切换) 2~3 个 点击按钮 / 路由跳转 状态管理逻辑(React Query / Zustand) 3~5 个 数据缓存、loading 状态、错误状态 👉 重点是分支覆盖,不是输入覆盖。
🧠 四、用「Given / When / Then」三步法写用例(非常实用)
写测试时不要想“要测几种情况”, 而是想:
- Given:给定一个初始状态
- When:当用户或系统做了某个动作
- Then:预期结果是什么
比如👇
xxxxxxxxxx111test('adds a hero when form is submitted', async () => {2// Given: 打开页面并输入表单3render(<SuperHeroesPage />);4fireEvent.change(screen.getByLabelText(/name/i), { target: { value: 'Batman' } });56// When: 点击提交7fireEvent.click(screen.getByText(/add hero/i));89// Then: 新英雄出现在列表中10expect(await screen.findByText(/Batman/)).toBeInTheDocument();11});✔️ 一条用例,就代表一次完整的“用户行为验证”。
🧩 五、一个通用策略:每个功能写 2~3 个测试即可
例如「添加英雄」功能:
测试目标 用例示例 ✅ 成功添加 输入正确信息 → 成功提示 ⚠️ 验证失败 不填内容 → 显示错误 ❌ 服务器错误 返回500 → 显示“添加失败” 这样写完后,这个功能几乎就“安全了”。 不需要 10 个输入组合的测试。
🧠 六、记住这句黄金法则
💬 “你不是在证明代码没错,而是在确保用户不会出问题。”
所以:
- 测“真实用户路径”
- 不测“极端数学组合”
- 测“可能变动的逻辑”
- 不测“不会出 bug 的静态内容”
📈 七、实践经验(真实团队中的标准)
团队类型 测试策略 初创团队 只测关键功能(10–20 条用例) 中型团队 每个业务模块 3–5 条核心用例 大型产品(有 CI) 关键逻辑全测(50–200 条用例) 即使是成熟的产品,也不会追求“全面覆盖”。 而是保证:
“核心功能永远不会因为重构崩掉。”
✅ 总结:测试数量黄金法则
层级 每个模块推荐用例数量 备注 逻辑函数 2~3 个 分支覆盖 表单 3~4 个 成功 / 校验 / 错误 API 逻辑 2~3 个 成功 / 失败 页面 3~5 个 行为路径 整体项目 30~50 个 中型项目就足够
1 - Introduction
测试非常重要

我们通常依赖手动测试,手动测试有很多缺点。

自动测试有下面的好处:

课程结构:

2 - Jest vs React Testing Library
同时需要Jest和RTL来写测试代码。


3 - Types of Tests

单元测试

集成测试

端到端测试

我们到底应该写哪种类型的测试?都要写,但是就像下图显示的那样,unit tests写的最多,integration tests数量居中,而E2E测试写的数量最少。
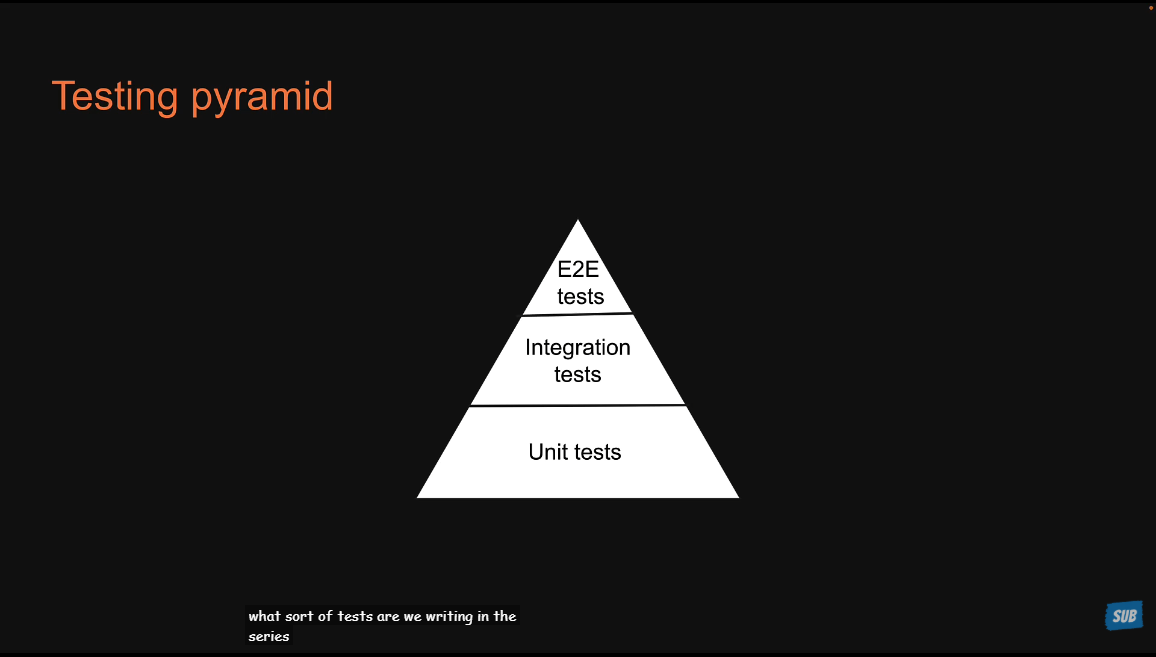
React Testing Library (RTL) 的核心设计理念是“测试组件的行为而不是实现细节”,其目标是让测试更接近用户如何实际使用应用程序的方式,从而提供更可靠的测试信心。

小结:

4 - What is a Test?
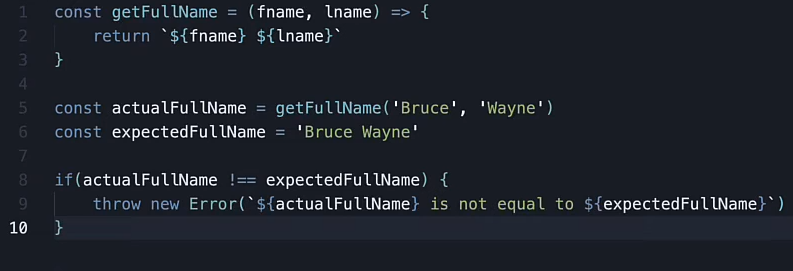
自动测试是什么?
是一段代码,当测试对象的真实输出与预期输出不一致时,会抛出错误。
下面是模拟测试代码的片段,测试流程就是这样的,当真实输出和预期输出不一致,就会报出有意义的错误。
5 - Project Setup
1、创建项目:npm create vite@latest react-testing,添加typescript。
因为vite创建项目默认没有安装jest和RTL,所以需要自己安装。可以使用下面的代码来查看是否安装了。
xxxxxxxxxx31npm list jest23npm list @testing-library/react如果显示-- (empty),说明没有安装。
因为这个课程是2022年的,到现在create-react-app命令已经不推荐了,jest也因为执行慢而不推荐了,所以我决定安装vitest和RTL,如果遇到jest的代码,我就搜索看怎么使用vitest来写,就这样了。
安装依赖:npm install -D vitest @testing-library/react @testing-library/jest-dom jsdom。
为什么还要安装jest-dom呢?
@testing-library/jest-dom虽然名字里有 “jest”, 但它不是 Jest 专属的库,而是一个“断言扩展库”。它的作用是: 👉 给测试框架(Jest、Vitest、Testing Library 等) 扩展出更多更自然的人类可读断言(matchers)。Vitest 直接兼容 Jest 的断言扩展。
为什么要安装jsdom?
💡
jsdom是一个用 纯 JavaScript 实现的“浏览器环境模拟器”。在 Node.js 中,没有浏览器、没有
window、没有document。 但 React 组件的渲染、事件监听、DOM 操作都依赖这些对象。 👉 所以我们需要jsdom来 在 Node 环境下伪造一个浏览器环境。
2、修改 vite.config.ts
打开 vite.config.ts,在配置里加上 test 字段 👇
xxxxxxxxxx201/// <reference types="vitest" />2import { defineConfig } from 'vitest/config'3import react from '@vitejs/plugin-react'45// https://vite.dev/config/6export default defineConfig({7 plugins: [8 react({9 babel: {10 plugins: [['babel-plugin-react-compiler']],11 },12 }),13 ],14 test: {15 globals: true, // 允许直接使用 describe/test/expect16 environment: 'jsdom', // 模拟浏览器环境17 setupFiles: './src/setupTests.ts', // 测试前的全局配置文件18 },19})203、在package.json里面添加测试脚本命令
xxxxxxxxxx51"scripts": {2 3 4 "test": "vitest",5}4、创建src/setupTests.ts
这个文件用来引入jest-dom的扩展断言:
xxxxxxxxxx31// src/setupTests.ts23import '@testing-library/jest-dom';这个文件的详细作用:
🧩 一、
setupTests.ts的作用是什么?
setupTests.ts(或setupTests.js)是一个 测试运行前的全局初始化文件。简单理解:
每次执行
npm run test,Vitest 会在运行任何测试文件之前先执行这个文件。它的作用包括:
- 注册测试全局匹配器(比如
jest-dom提供的自定义断言)- 设置全局 mock(如
fetch、localStorage等)- 初始化测试环境(如 RTL 的
cleanup())- 配置全局变量(如自定义环境变量、Polyfill)
✅ 举个例子:
src/setupTests.tsxxxxxxxxxx11import "@testing-library/jest-dom"; // 注册自定义匹配器,比如 toBeInTheDocument()这样你在测试文件中就可以直接写:
xxxxxxxxxx11expect(screen.getByText("Hello")).toBeInTheDocument();否则 TypeScript 会报错:
Property 'toBeInTheDocument' does not exist on type 'Assertion'.
⚙️ 二、这个文件“用在哪里”?
Vitest 在你的
vite.config.ts里识别它。 我们在配置文件中这样写👇:xxxxxxxxxx51test: {2globals: true,3environment: "jsdom",4setupFiles: "./src/setupTests.ts",5},这表示:
在每个测试文件运行前,先执行一次
setupTests.ts文件的内容。这就像 Jest 里常用的
setupFilesAfterEnv一样的概念。🚀 三、
npm run test到底运行哪个文件?1️⃣ 执行命令
当你运行:
xxxxxxxxxx11npm run test其实执行的是
vitest命令。这通常在
package.json里配置的,比如:xxxxxxxxxx51{2"scripts": {3"test": "vitest"4}5}2️⃣ Vitest 会自动:
- 读取
vite.config.ts的test配置。- 根据
include规则(默认为**/*.{test,spec}.{js,ts,jsx,tsx})加载所有测试文件。- 在执行每个测试文件之前,先运行一次
setupTests.ts。- 按顺序执行所有测试。
📦 四、执行流程总结图
xxxxxxxxxx111npm run test2↓3调用 Vitest CLI4↓5读取 vite.config.ts6↓7执行 setupTests.ts(全局初始化)8↓9扫描所有匹配 *.test.ts(x)10↓11逐个运行测试文件🧠 五、总结对照表
文件/命令 作用 是否自动执行 setupTests.ts在所有测试运行前执行的初始化逻辑 ✅ 是 vite.config.ts测试环境配置(jsdom、globals等) ✅ 是 npm run test启动测试执行流程 ✅ 是 *.test.tsx实际编写的测试用例文件 ✅ 是
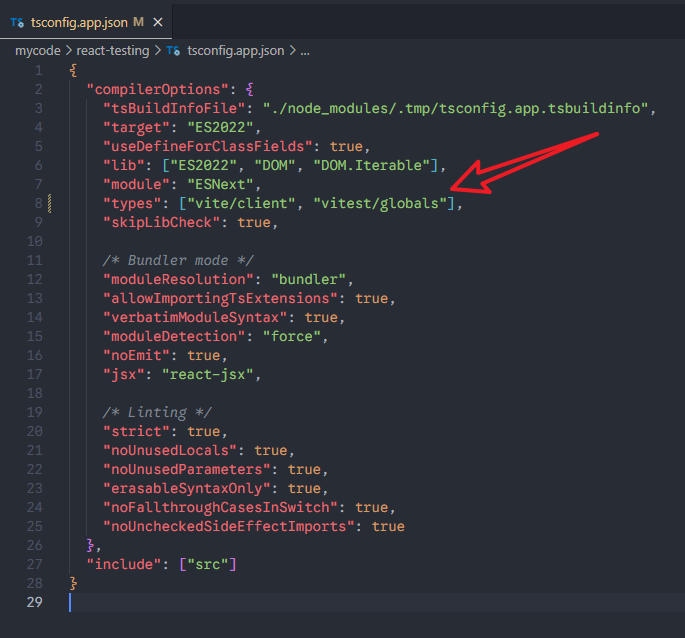
5、声明vitest相关的types
xxxxxxxxxx91// tsconfig.json235{6 "compilerOptions": {7 "types": ["vitest/globals"]8 }9}给 TypeScript 告诉「我在用 Vitest」。
如果tsconfig.json文件的references是引用的其它文件,比如说tsconfig.app.json,那么就需要在这个文件里面改:
6、创建测试文件
比如说我创建App.test.tsx这个测试文件,简单测试一下:
xxxxxxxxxx241// src/App.test.tsx23import { render, screen, fireEvent } from "@testing-library/react";4// 引入这些函数,可以得到类型提示。虽然不引入也可以5import { describe, it, expect } from "vitest";6import App from "./App";78describe("App component", () => {9 it("renders the heading and button correctly", () => {10 render(<App />);11 // 断言标题是否存在12 expect(screen.getByText(/Vite \+ React/i)).toBeInTheDocument();13 // 断言按钮是否存在14 expect(screen.getByRole("button", { name: /count is 0/i })).toBeInTheDocument();15 });1617 it("increments count when button is clicked", () => {18 render(<App />);19 const button = screen.getByRole("button", { name: /count is 0/i });20 fireEvent.click(button);21 expect(screen.getByRole("button", { name: /count is 1/i })).toBeInTheDocument();22 });23});24三个函数的意义:
describe:像章节标题,用来“分组”一组相关的测试;
it(或test):一个具体的测试用例(Test Case);
expect:测试的核心断言,用来“验证”结果是否正确。
6 - Running Tests
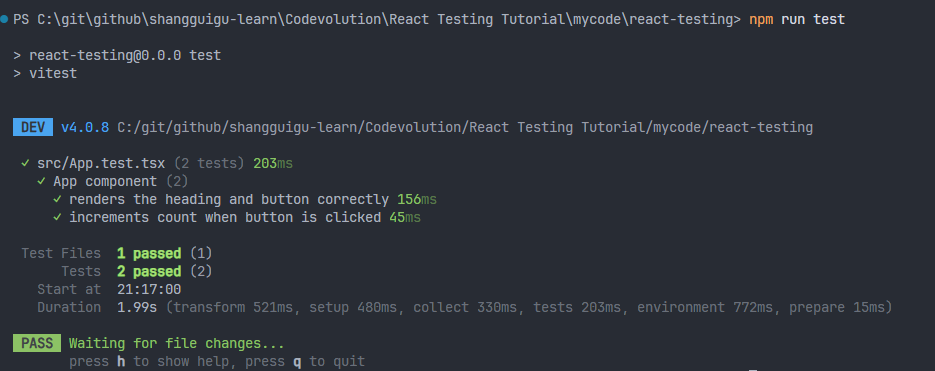
上节课已经编写了App.tsx的测试文件,可以使用npm run test来看一下测试效果。
报错:Error: [vitest-pool]: Timeout starting forks runner.
解决办法:
在 Windows 上运行时,有时防病毒软件(尤其是 360、Defender、McAfee) 会阻止 Node 创建子进程,Vitest 的多进程初始化就会超时。
✅ 解决方法:
将package.json里面的命令改为:
test: vitest --pool=threads。改用线程池模式。
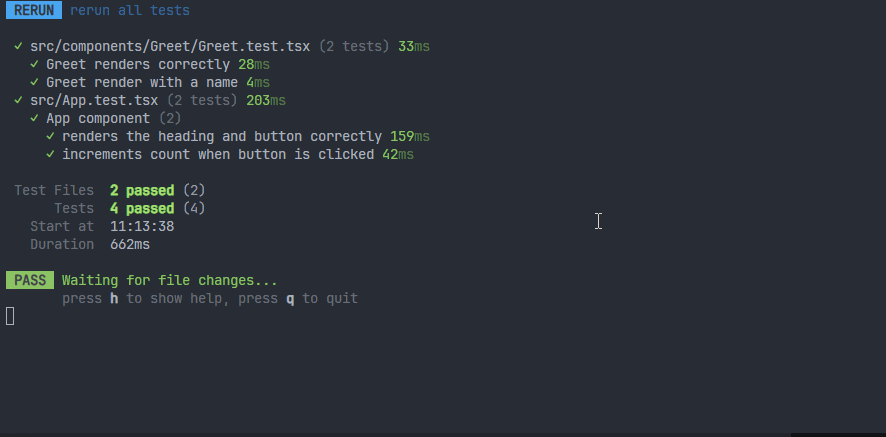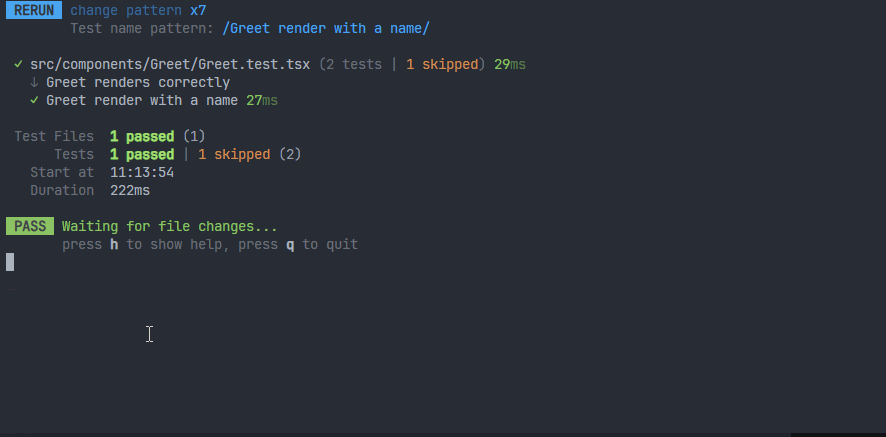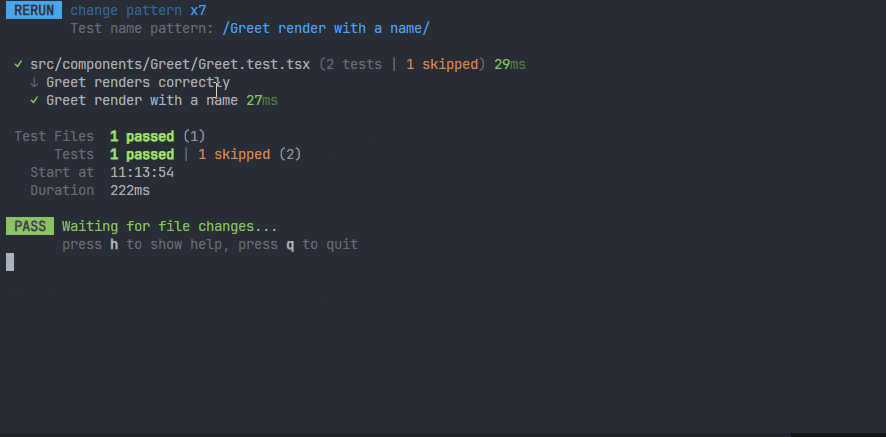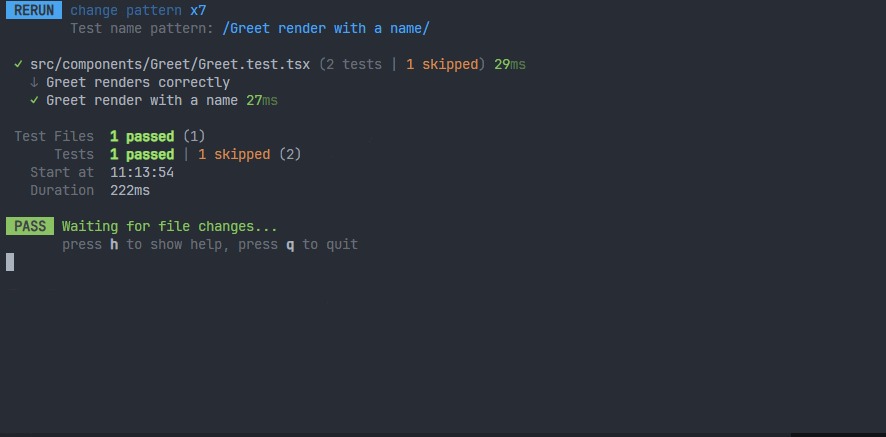
重新测试,可以看到一个测试文件,两个测试用例测试通过了:
7 - Anatomy of a Test
anatomy:解剖。
这节课来学习test文件的结构,解剖一下。按照老师的测试文件来讲解,test与it类似。
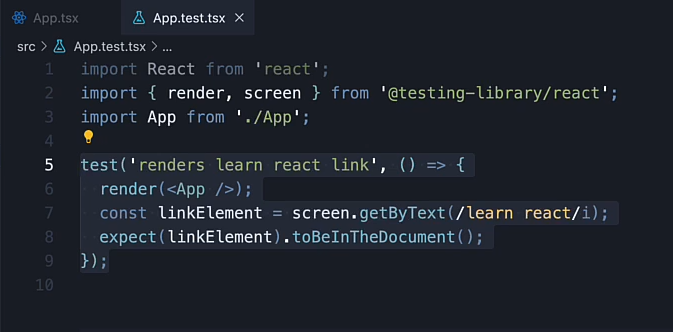
test函数的作用:定义一个独立的测试用例。

| 参数 | 类型 | 描述 |
|---|---|---|
name | string | 测试用例的描述名称。 |
fn | function | 实际包含测试逻辑的回调函数。 |
timeout | number | 可选参数。该测试用例的最大执行时间(毫秒)。 |
- render函数:模拟浏览器环境,生成可供检查的 DOM。
- screen对象:查找和操作 DOM 节点,就像用户做的那样。
- expect函数:是 断言(Assertion) 的核心。它的作用是 包裹一个你想要测试的“实际值”,并为你提供一系列的 匹配器(Matchers) 来对这个值进行验证。
- toBeInTheDocument():一个用于测试DOM元素的匹配器(Matcher),它断言(Assert)被
expect()包裹的 DOM 元素 当前是否存在于文档的 DOM 树中。
8 - Your First Test
创建一个很简单的组件:
xxxxxxxxxx51// src\components\Greet\Greet.tsx23export const Greet = () => {4 return <div>Hello</div>;5};编写测试文件:
xxxxxxxxxx111// src\components\Greet\Greet.test.tsx23import { render, screen } from "@testing-library/react";4import { Greet } from "./Greet";56it("Greet renders correctly", () => {7 render(<Greet />);8 // 这里的文字写成 /hello/i ,意思是忽略大小写9 const textElement = screen.getByText(/hello/i);10 expect(textElement).toBeInTheDocument();11});运行测试,通过:
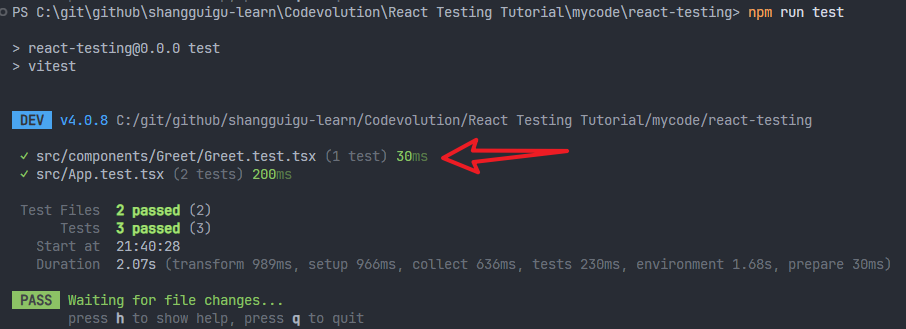
9 - Test Driven Development
TDD的标准是下面这样:

但是TDD想要真的实现起来,困难重重,原因是初期学习成本高、时间压力、遗留系统问题等等,所以现实使用的时候,需要妥协:
- TPDD(测试前置驱动开发)/ Test-First 模式: 这是最常见的变种。开发者在实现功能之前会思考测试用例,并在开发功能的过程中(或者功能完成后立刻)编写测试。这比严格的 TDD 更灵活,但仍能获得 TDD 的大部分好处(清晰的设计和高覆盖率)。
- 核心业务/ Bug 修复时 TDD: 许多团队只对最核心、最复杂的业务逻辑或在修复关键 bug 时使用 TDD。修复 bug 时,“先写一个能重现 bug 的测试(红),然后修复代码(绿)”,是 TDD 模式最立竿见影的应用。
- 新项目阶段 TDD,老项目阶段搁置: 在项目初期,一切都是全新的,TDD 相对容易推行。但随着项目规模变大,技术债积累,代码测试性变差,坚持 TDD 的成本会显著增加,导致团队在后续迭代中放弃严格的 TDD 流程。
这节课只是介绍一下按照TDD来写的流程,了解即可。
1、根据需求,编写测试用例
需求:Greet should render the text hello and if a name is passed into the component, it should render hello followed by the name.
xxxxxxxxxx161// src\components\Greet\Greet.test.tsx23import { render, screen } from "@testing-library/react";4import { Greet } from "./Greet";56it("Greet renders correctly", () => {7 render(<Greet />);8 const textElement = screen.getByText(/hello/i);9 expect(textElement).toBeInTheDocument();10});1112it("Greet renders with a name", () => {13 render(<Greet name="Anderson" />);14 const textElement = screen.getByText("Hello Anderson");15 expect(textElement).toBeInTheDocument();16});这时候就可以把测试运行起来了npm run test,肯定是会看到报错的,然后就根据报错把组件代码编写完成。
2、编写组件代码,直到测试通过
xxxxxxxxxx51// src\components\Greet\Greet.tsx23export const Greet = ({ name }: { name?: string }) => {4 return <div>Hello {name}</div>;5};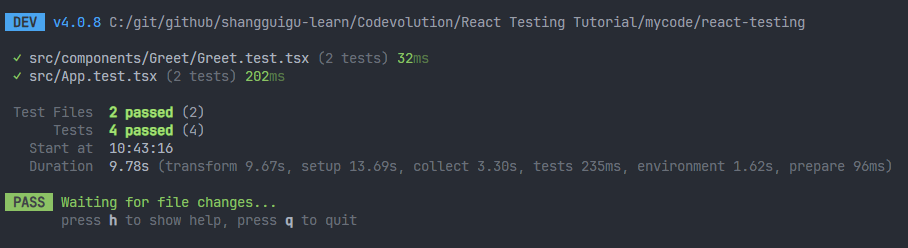
第三步就不展示了,因为案例代码很简单。总之,这节课就是演示一下TDD的开发流程,不一定要按这个流程来做。
10 - Jest Watch Mode
这节课学习了解jest的watch模式,watch模式是jest命令的一个选项,默认选中的。jest会监听上一次commit后变更过的文件,只执行这些变更过的文件。

由于我使用的是vitest,我就以vitest来说明:
默认情况下,Vitest 会以 “watch 模式(监视模式)” 启动,除非你明确加上 run 参数。
xxxxxxxxxx41"scripts": {2 3 "test": "vitest --pool=threads"4 }👉 默认进入 **watch 模式
xxxxxxxxxx41"scripts": {2 3 "test": "vitest run --pool=threads"4 }👉 进入 一次性运行模式(不 watch)
概念
Watch 模式就是:Vitest 会 持续监听你的文件变化(包括源码文件 .ts, .tsx、测试文件 .test.ts、配置文件等),只要检测到文件变动,它会 自动重新运行相关的测试。
好处
| 优点 | 说明 |
|---|---|
| ⚡ 快速反馈 | 你修改代码后不需要手动再跑 npm run test,Vitest 会自动检测到变化并重新运行测试。 |
| 🎯 局部测试 | Vitest 会智能判断哪些测试受影响,只重新运行相关的测试文件,而不是所有测试,提高速度。 |
| 🔁 提高开发效率 | 可以边写代码边看测试结果实时刷新,类似于开发服务器的 “热重载(HMR)” 体验。 |
| 🧩 集成 IDE | 在 VSCode 等编辑器里运行 watch 模式时,可以结合断点调试、错误提示、快照测试等工具使用。 |
11 - Filtering Tests
运行测试之后,按h键可以显示help菜单,里面有一些命令:
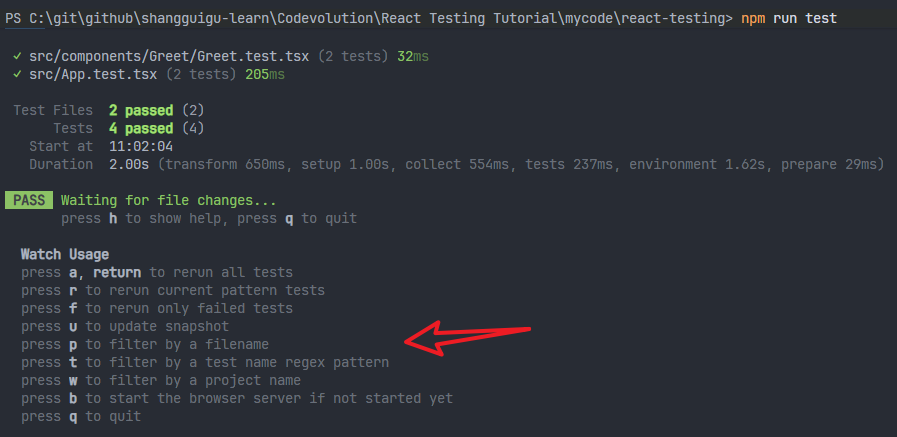
1、需求:当前过滤只测试一个文件。
可以按p键,然后输入文件名称,使用方向键来选择文件,选中之后按enter即可。
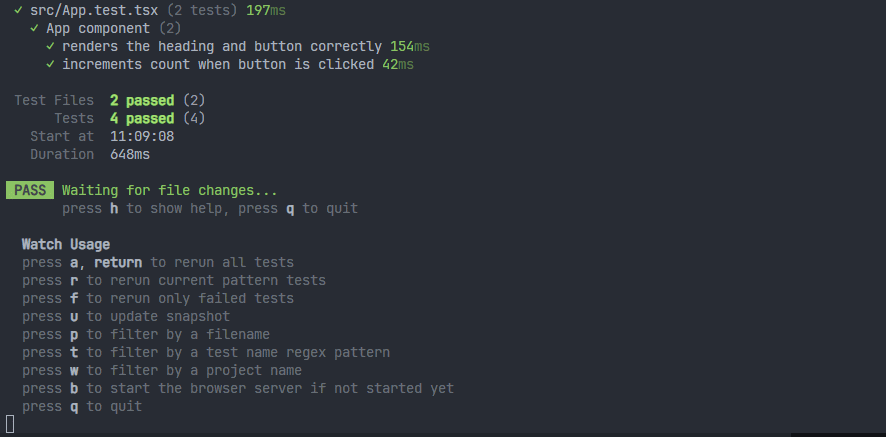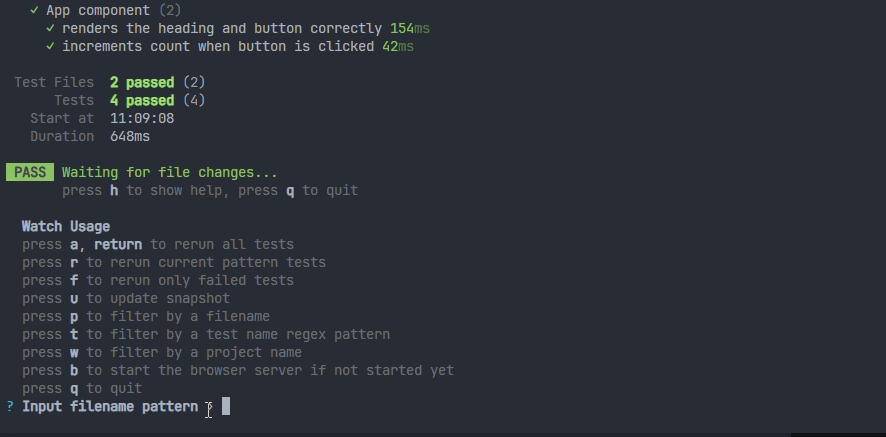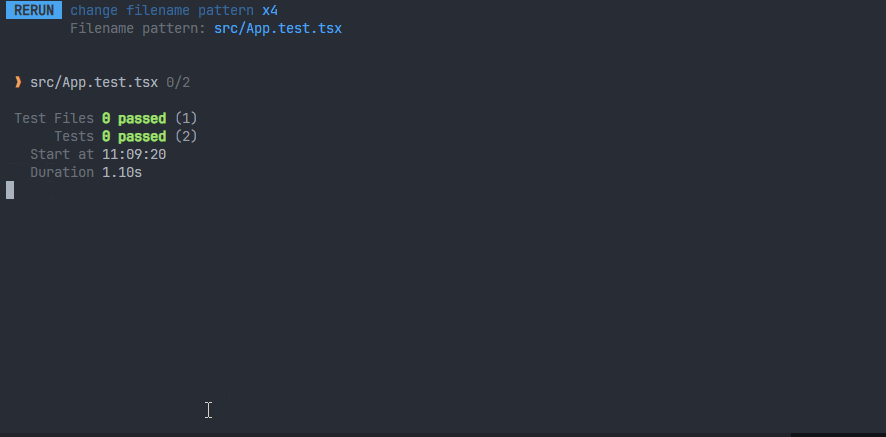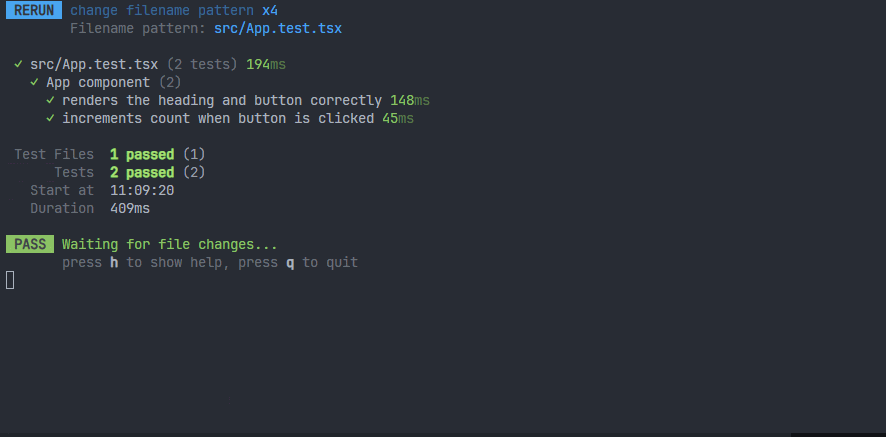
这个就是在watch模式下,能够专注于测试某个文件(修改其它的文件,不会触发watch监听测试),性能会更加好。如果想还原,可以输入a键,就会测试所有文件。
2、需求:当前过滤只测试某个测试用例。
可以按t键,输入起的测试名称,就是it或者test的第一个参数,不需要完整输入,因为搜索是模糊搜索,就会出现一些选项,使用方向键来选择,使用enter键来选中。
这个就是在watch模式下,能够专注于测试某个测试用例(修改其它的测试用例,不会触发watch监听测试),性能会更加好。如果想还原,可以输入a键,就会测试所有文件。
3、可以使用test.only()或者it.only()来指定一个测试文件里面测试哪些用例。比如说这样:
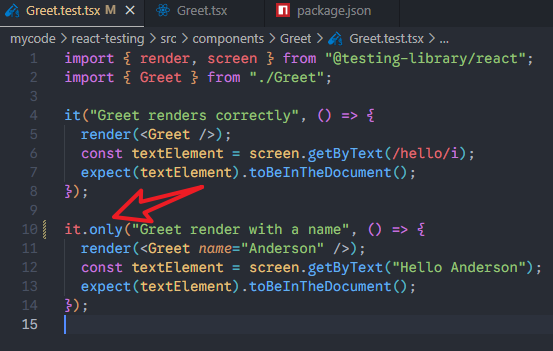
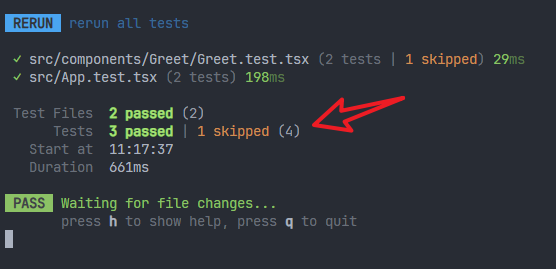
测试之后会显示有一个测试用例被跳过了。
4、可以使用test.skip()或者it.skip()来指定一个测试文件跳过哪些测试用例。比如说:
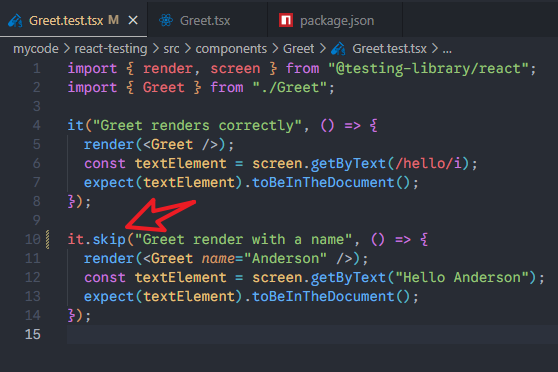
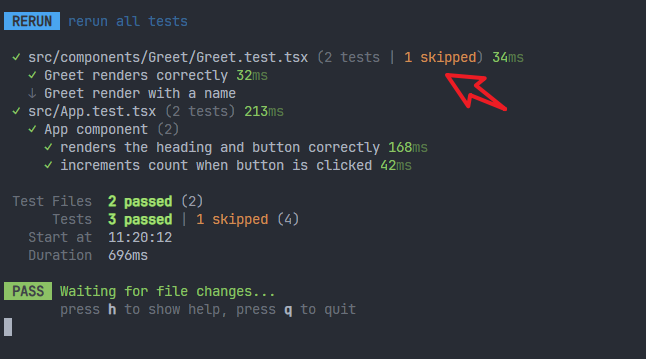
测试之后就会显示有一个测试用例被跳过了。
only和skip方法,可以结合上面的过滤一起使用,性能会更好。
12 - Grouping Tests
如果你想让测试用例组织成组,可以使用describe函数,它用于组织测试结构、分组测试用例,让测试代码更清晰、可维护。
第一个参数是分组的名称;第二个参数是一个函数,包含测试用例。

将Greet.test.tsx文件里面的测试用例,都放到describe里面去,分组名称是Greet。
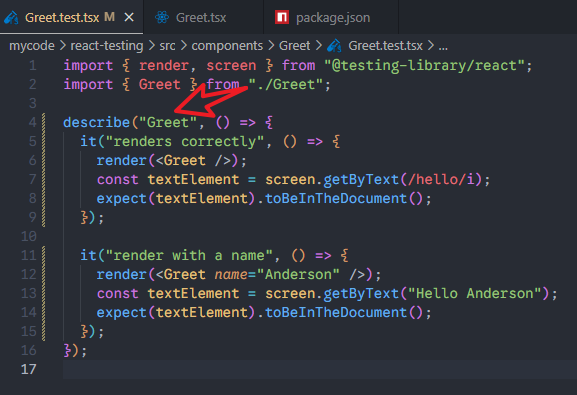
可以看到,制定了分组名称之后,测试结果看上去就很有层次了。
1、describe可以使用only和skip方法,来只测试或者跳过测试。
2、describe可以嵌套使用
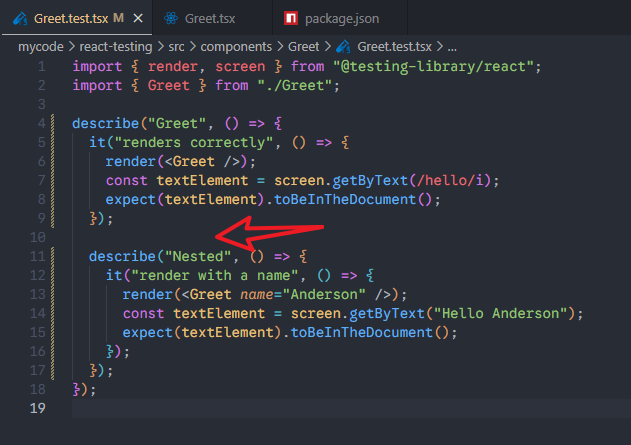
测试结果:
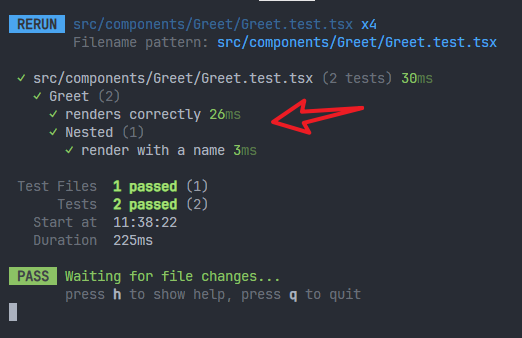
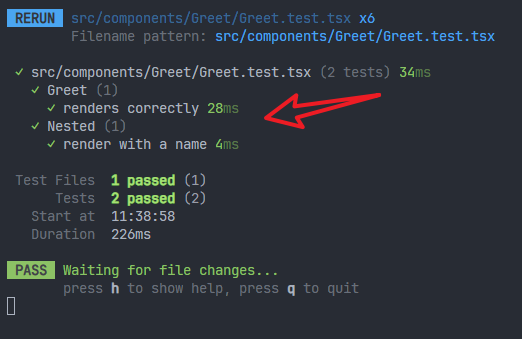
3、一个测试文件里面可以有多个describe
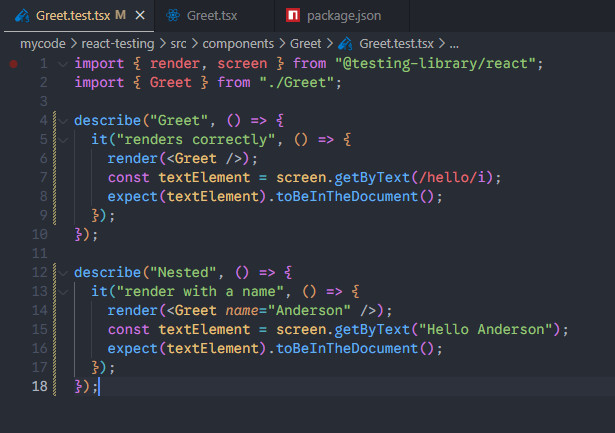
测试结果:
13 - Filename Conventions
jest认为合法的测试文件名称,约定如下:

推荐方法是将测试文件靠近你需要测试的代码文件,这样相对引入路径会短一些。
那么vitest里面的约定是什么呢?
Vitest 默认会扫描以下几种命名模式的文件,并将它们识别为测试文件:
xxxxxxxxxx21**/*.test.{js,ts,jsx,tsx,mjs,cjs}2**/*.spec.{js,ts,jsx,tsx,mjs,cjs}也就是说,只要文件名符合:
- 以
.test或.spec结尾 - 后缀是支持的 JS/TS 格式
当然vitest允许你在配置文件(通常是 vitest.config.ts)里自定义测试文件的匹配规则:
xxxxxxxxxx91// vitest.config.ts2import { defineConfig } from 'vitest/config'34export default defineConfig({5 test: {6 include: ['src/**/*.test.ts', 'src/**/*.spec.ts'],7 exclude: ['node_modules', 'dist'],8 },9})你可以自由调整,比如:
测试文件全部放在
__tests__文件夹内:xxxxxxxxxx11include: ['src/**/__tests__/**/*.{test,spec}.{ts,tsx}']或者只测试
.test.tsx文件:
xxxxxxxxxx11include: ['src/**/*.test.tsx']推荐的方式就是将测试文件和源文件放在一起,这样配置文件也不用改了:
xxxxxxxxxx71src/2 components/3 Button.tsx4 Button.test.tsx5 utils/6 math.ts7 math.test.ts14 - Code Coverage
metric:度量、指标。
代码覆盖度,包含下面四个指标。

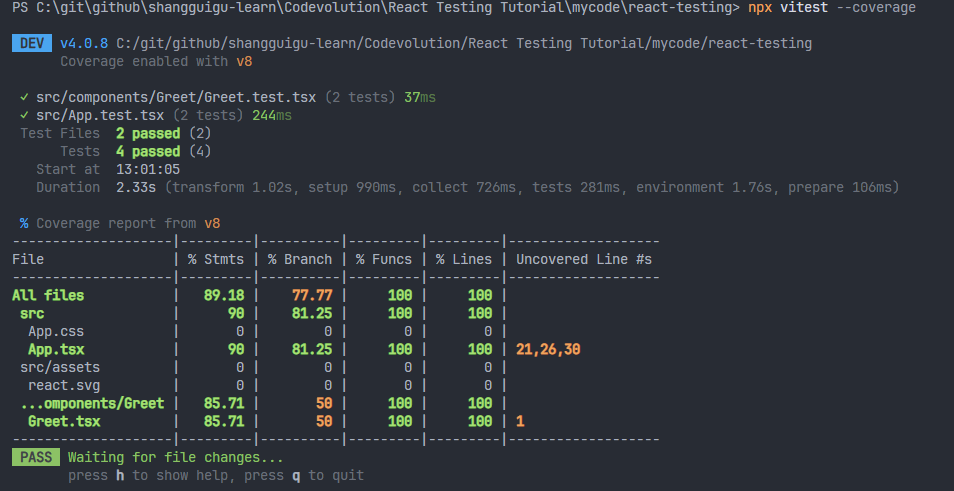
运行:npx vitest --coverage
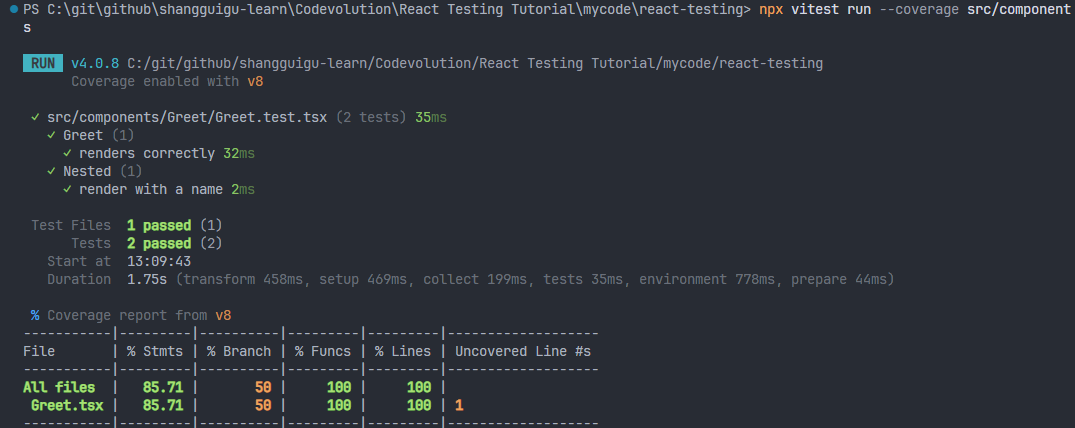
1、指定目录或文件
npx vitest run --coverage src/components
后面可以使用空格隔开,添加多个目录或文件地址。
2、报告的类型
reporter 类型(--coverage.reporter)
| Reporter | 输出位置 | 说明 |
|---|---|---|
text | 控制台 | 详细文本报告 |
text-summary | 控制台 | 简略总结 |
html | coverage/index.html | 图形化网页报告 |
json | coverage/coverage-final.json | 原始数据,供分析 |
json-summary | coverage/summary.json | 汇总数据 |
lcov | coverage/lcov.info | 常用于 CI 工具,如 Codecov / Coveralls |
默认是输出text 和 html,text输出在terminal控制台里面,html是命令执行之后,会在项目根目录插件一个coverage的文件夹,里面存放的html文件。
3、配置
可以在vite.config.ts里面配置coverage属性,比如说coverage.exclude属性,可以排除一些类型的文件。
xxxxxxxxxx231// vitest.config.ts2import { defineConfig } from 'vitest/config'34export default defineConfig({5 test: {6 coverage: {// 覆盖率配置7 provider: 'v8', // 表示使用哪种引擎生成覆盖率数据,'c8' 也可以8 reporter: ['text', 'html', 'lcov'],// 控制生成什么格式的报告9 reportsDirectory: './coverage',// 指定生成的覆盖率报告输出到哪个文件夹10 include: ['src/**/*.{ts,tsx}'],// 控制哪些文件被统计11 exclude: ['node_modules/', 'dist/', '**/*.d.ts'],// 控制哪些文件被忽略12 all: true,// 表示即使某些文件没有被测试文件导入,也要把它们包含在覆盖率统计中。你想知道“哪些模块完全没写测试”,就必须开启这个选项。13 clean: true,// 每次运行测试时,是否先清空旧的覆盖率数据。14 thresholds: {// 设置覆盖率最低阈值。15 lines: 80,// 每个文件的行覆盖率下限16 functions: 80,// 函数覆盖率下限17 branches: 70,// 条件分支覆盖率下限18 statements: 80,// 所有语句覆盖率下限19 },20 skipFull: false,// 是否在报告中跳过覆盖率 100% 的文件21 },22 },23})这些配置在CI/CD时很有效,可以实时查看覆盖率。
15 - Assertions
断言(Assertion) 指的是:在测试中,用来“判断结果是否符合预期”的语句。

✅ 举个例子
xxxxxxxxxx61import { expect, test } from 'vitest'23test('adds two numbers', () => {4 const result = 1 + 25 expect(result).toBe(3) // ✅ 断言:结果应该等于36})这里:
expect(result)创建了一个“期望对象”(expectation).toBe(3)是一个 断言(assertion)- 如果
result !== 3,测试就会失败。
expect
vitest中通常使用expect来创建一个期望对象,与一个匹配器matcher函数一起使用。

断言的基本结构:
xxxxxxxxxx11expect(实际值).匹配器(期望值)matchers
vitest自身提供的matchers可以在这里找到:https://vitest.dev/api/expect.html。由于vitest兼容jest,所以jest的matchers也可以在vitest里面使用,在这里可以找到:https://jestjs.io/docs/using-matchers。
但上面这些都是针对JS的测试,我们在react项目里面还要针对UI和DOM进行测试。这时候使用的是jest-dom库提供的matchers。在这里可以找到:https://github.com/testing-library/jest-dom
16 - What to test?
在react项目中,到底要测试什么呢?
测试组件渲染;如果有props,那么要加上props一起测试渲染;测试组件的不同状态; 测试组件如何响应交互事件。

不要测什么?
实现细节不要测;第三方包的代码不要测(但是如果组件使用了第三方的代码,那么需要测试自己的组件);从用户角度看不重要的代码不要测。
17 - RTL Queries
编写一个测试用例的过程就是下面的步骤:
1、渲染组件,使用RTL提供的render方法
2、找到组件中的一个被渲染的元素
3、断言被找到的元素,看是否通过测试

那怎么找到元素呢?这时候就要使用RTL queries相关的方法了。分为查找单个元素和查找多个元素。
方法后面的..表示查找的各种依据,比如说getByRole、getByText等等,老师只是总结了一些前缀,完整的方法就是像getByText这样。
RTL中的查询方法和DOM testing library的方法使用方法大部分一致,只是RTL中的查询方法,不需要写第一个参数,因为第一个参数已经绑定到document对象了。
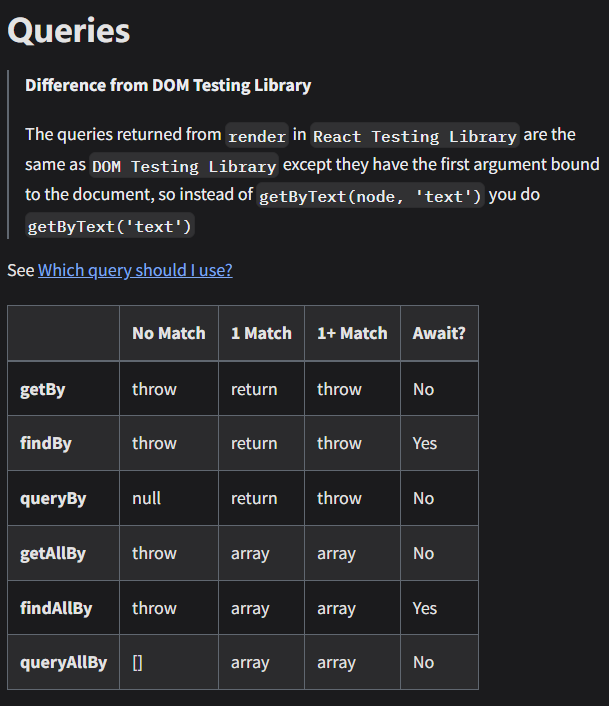
RTL相关的查询方法,可以从https://testing-library.com/docs/react-testing-library/cheatsheet找到,使用方法可以直接看testing-library里面的core API。https://testing-library.com/docs/queries/byrole
下面的几节课要开始讲解getBy开头的查询方法。

18 - getByRole
getByRole方法根据给定的role来查询元素。role指的是ARIA role,用于告诉屏幕阅读器、盲文显示器等辅助技术,某个元素在页面上扮演的功能角色是什么。

很多HTML语意元素默认有role属性,比如说button的role属性值就是button。在这里可以查询HTML元素默认的role属性值https://www.w3.org/TR/html-aria/#docconformance。或者问AI即可。
如果你使用的元素没有默认role属性,或者你想自定义role属性,可以使用role=xxx来指定。

创建application.tsx文件,在App.tsx里面引入它,删除App.test.tsx文件,因为这个课程之后的事情都与它无关了。
xxxxxxxxxx411// src\components\Application\Application.tsx23export const Application = () => {4 return (5 <>6 <h1>Job application form</h1>7 <h2>Section 1</h2>8 <p>All fields are mandatory</p>9 <span title="close">X</span>10 <img src="https://via.placeholder.com/150" alt="a person with a laptop" />11 <div data-testid="custom-element">Custom HTML element</div>12 <form>13 <div>14 <label htmlFor="name">Name</label>15 <input type="text" id="name" placeholder="Fullname" value="Vishwas" onChange={() => {}} />16 </div>17 <div>18 <label htmlFor="bio">Bio</label>19 <textarea id="bio" />20 </div>21 <div>22 <label htmlFor="job-location">Job location</label>23 <select id="job-location">24 <option value="">Select a country</option>25 <option value="US">United States</option>26 <option value="GB">United Kingdom</option>27 <option value="CA">Canada</option>28 <option value="IN">India</option>29 <option value="AU">Australia</option>30 </select>31 </div>32 <div>33 <label>34 <input type="checkbox" id="terms" /> I agree to the terms and conditions35 </label>36 </div>37 <button disabled>Submit</button>38 </form>39 </>40 );41};不要担心这个form组件的测试文件该怎么写?老师这节课主要是讲解使用getByRole方法,来查询主要的交互元素是否渲染了。
xxxxxxxxxx211// src\components\Application\Application.test.tsx23import { render, screen } from "@testing-library/react";4import { Application } from "./Application";56describe("Application", () => {7 test("renders correctly", () => {8 render(<Application />);9 const nameElement = screen.getByRole("textbox");10 expect(nameElement).toBeInTheDocument();1112 const jobLocationElement = screen.getByRole("combobox");13 expect(jobLocationElement).toBeInTheDocument();1415 const termsElement = screen.getByRole("checkbox");16 expect(termsElement).toBeInTheDocument();1718 const submitButtonElement = screen.getByRole("button");19 expect(submitButtonElement).toBeInTheDocument();20 });21});测试看一下:
19 - getByRole Options
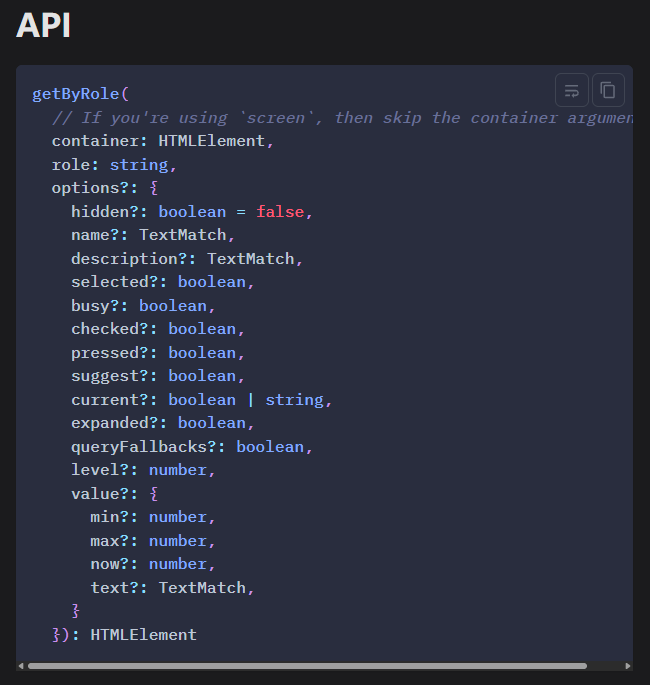
这节课来学习getByRole的第二个参数里面的一些配置参数,第二个参数是一个对象,里面有很多参数。全部参数如下:
1、name参数
在Application组件里面,添加一个textarea组件。
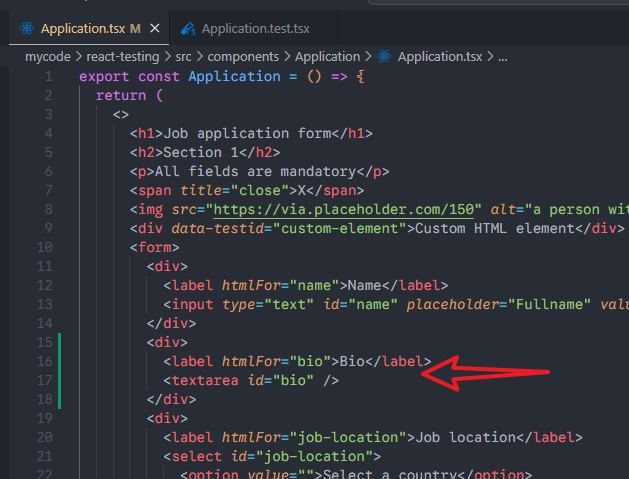
可以看到测试报错:
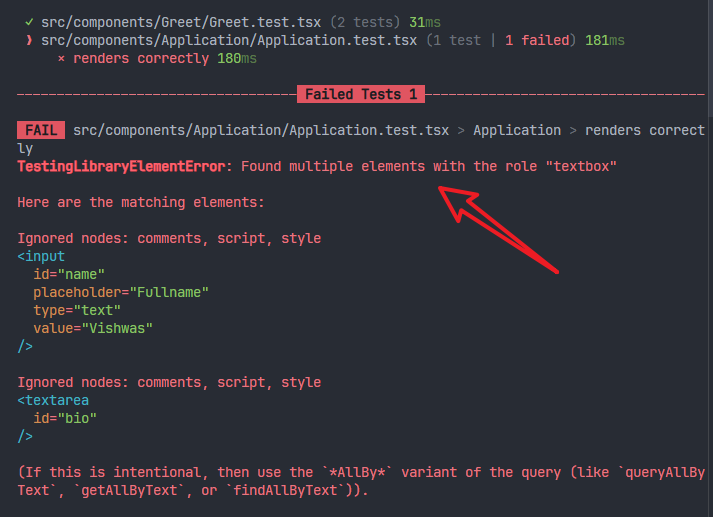
提示信息很清楚,就是找到了多个符合role="textbox"的元素。
可以添加name属性来解决。name属性指的是什么呢?
1、对于表单元素(如 <input>、<textarea>、<select>),它们的 name 通常由关联的 <label> 元素提供。
2、对于大多数具有文本内容的元素,name 就是它的可见文本。
| HTML 元素 | 预期 name 属性的值 |
|---|---|
<button>Submit</button> | "Submit" |
<a href="...">Home Page</a> | "Home Page" |
<h1>Welcome!</h1> | "Welcome!" |
3、如果元素没有可见文本或标签,但开发者使用了 ARIA 属性来提供名称,那么 name 属性就是这些 ARIA 属性的值。

所以,测试代码可以这样改:
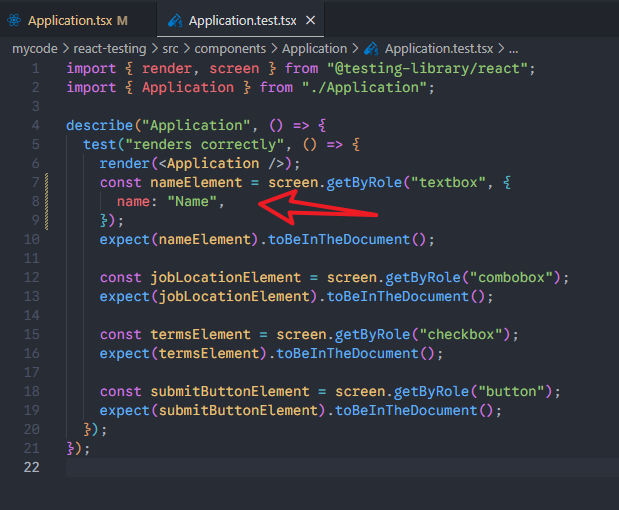
测试OK。
2、level参数
level参数对于role=heading的元素有用,因为h1~h6标签的role都是heading。
需求:测试h1和h2元素都渲染成功。
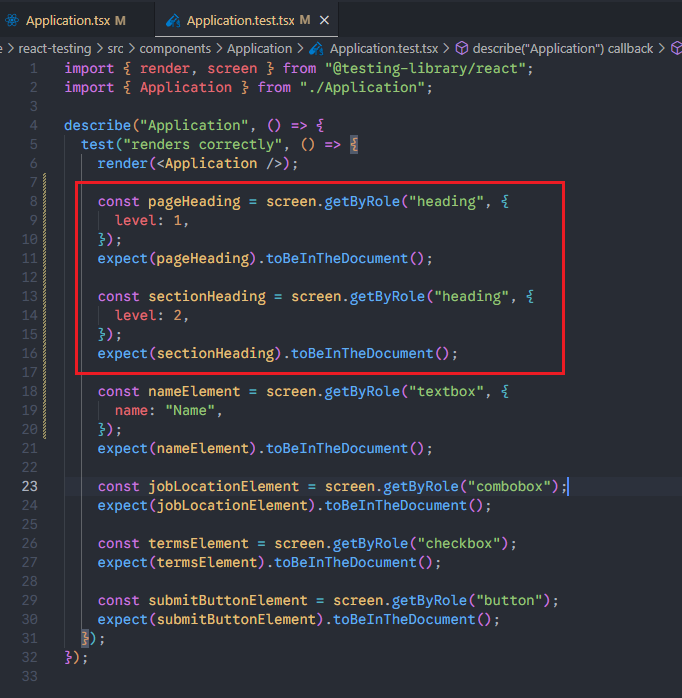
测试OK。
老师说getByRole应该是查询的第一选择,如果它不管用,再考虑其它的。
20 - getByLabelText
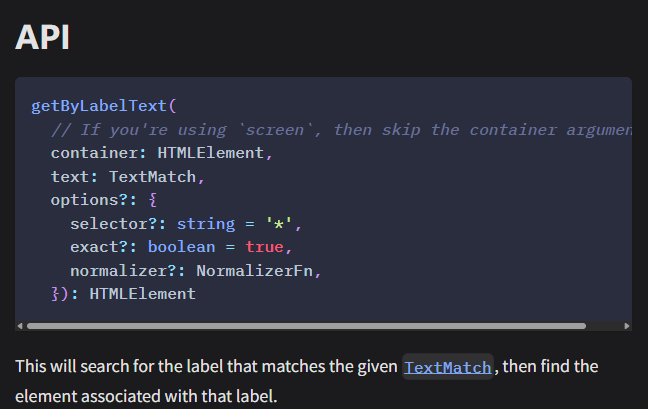
作用:通过表单元素的可见标签文本来查找该表单元素,用于获取与特定标签(Label)关联的表单控件。
比如说有下面的HTML结构:
xxxxxxxxxx21<label for="email-input">Email Address</label>2<input id="email-input" type="email" />那么就可以根据label标签文本Email Address,来找到与之相关的input输入框。
相关是通过label元素的for属性(react中就是htmlFor属性),指定为input元素的id属性的值。

1、基本使用
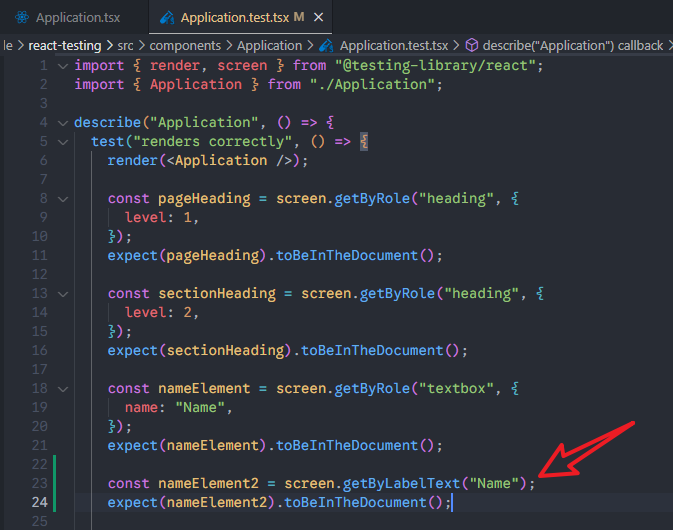
测试OK。
2、即使是wrapper的形式,也可以使用
这种情况称为“包裹式关联”,label上不需要添加for属性。
比如说Application.tsx里面有这段代码:
xxxxxxxxxx51<div>2 <label>3 <input type="checkbox" id="terms" /> I agree to the terms and conditions4 </label>5</div>还是可以通过label里面的文本来查询到相应的input。

测试OK。
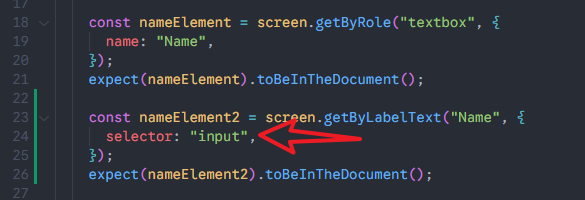
3、optional参数
假设多个labe里面的文本内容相同,此时可以指定selector参数为具体的元素名称,来查找。
21 - getByPlaceholderText
这个方法根据元素的placeholder属性的值来查找匹配,这个很好理解、很简单。

Application组件里面有一个指定了placeholder属性的元素:

使用getByPlaceholderText来查找:

测试OK。
22 - getByText
作用:通过元素的文本内容(Text Content)来查找 DOM 节点。可以用它来查找几乎所有非表单元素中的文本内容,但是最好只用来查找p、div、span这些元素,因为查找方法是有优先级的,getByRole的优先级最高。

需求:查找这个p元素。
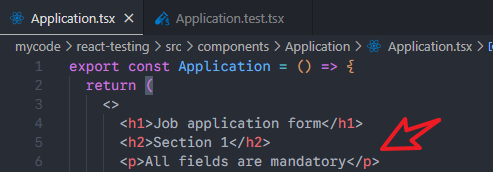
查找代码,测试OK:

23 - getByDisplayValue
这个方法查找匹配展示值的元素,通常是input、textarea、select。

需求:为input设置value属性,根据value查找这个input。

测试OK。

24 - getByAltText

需求:根据alt属性值,查询元素。
xxxxxxxxxx11<img src="https://via.placeholder.com/150" alt="a person with a laptop" />代码:

测试OK。
25 - getByTitle

需求:根据title属性值,查询元素。
xxxxxxxxxx11<span title="close">X</span>代码:

测试OK。
26 - getByTestId
如果上面的几个方法都不行,那么就使用这种方法。添加data-testid属性即可。

需求:根据testid来查询元素。
xxxxxxxxxx11<div data-testid="custom-element">Custom HTML element</div>代码:

测试OK。
27 - Priority Order for Queries
上面学习的8种方法是有优先级的:
| 优先级 | 查询方法 | 场景和目的 | 示例 |
|---|---|---|---|
| 1. 语义和角色 | getByRole | 查找可交互元素(按钮、链接、输入框、图片、列表等)。这是 RTL 最推荐的方法,因为它基于 WAI-ARIA 规范。 | screen.getByRole('button', { name: /save/i }) |
| 2. 标签 | getByLabelText | 查找与可见标签关联的表单元素(输入框、选择框等)。强制保证了表单的可访问性。 | screen.getByLabelText(/password/i) |
| 3. 占位符 | getByPlaceholderText | 查找带有特定 placeholder 的输入框。但请注意,placeholder 不应用于可访问性名称,应作为辅助查询。 | screen.getByPlaceholderText('Enter email') |
| 4. 文本内容 | getByText | 查找任何元素的纯文本内容。最适合查找静态文本、标题、段落等非交互元素。 | screen.getByText('Welcome to the app') |
| 5. 显示值 | getByDisplayValue | 查找当前显示特定值的表单元素(例如,已填写的输入框或选择框)。 | screen.getByDisplayValue('John Doe') |
| 6. 替代文本 | getByAltText | 查找图片(<img>)或自定义控件(如 SVG 图标)的 alt 文本。 | screen.getByAltText('Company Logo') |
| 7. 标题 | getByTitle | 查找带有 title 属性的元素。通常用于提供额外提示信息。 | screen.getByTitle('Close Window') |
| 8. 测试 ID | getByTestId | 查找带有 data-testid 属性的元素。这是最后的选择,仅用于那些没有其他语义或文本标识的元素。 | screen.getByTestId('loading-spinner') |
